
How is DNA Sequenced?
This article is part 4 of the Food Genomics column published by Food Safety Tech. Read the original article here.
A guide through the genomics language barrier.
By Sanjay K. Singh, Douglas Marshall, Ph.D., Gregory Siragusa, Ph.D.
Here is a prediction. Within the next year or years, at some time in your daily work life as a food safety professional you will be called upon to either use genomic tools or to understand and relay information based on genomic tools for making important decisions about food safety and quality. Molecular biologists love to use what often seems like a foreign or secret language. Rest assured dear reader, these are mostly just vernacular and are easily understood once you get comfortable with a bit of the vocabulary. In this the fourth installment of our column we progress to give you another tool for your food genomics tool kit. We have called upon a colleague and sequencing expert, Dr. Sanjay Singh, to be a guest co-author for this topic on sequencing and guide us through the genomics language barrier.
The first report of the annotated (labeled) sequence of the human genome occurred in 2003, 50 years after the discovery of the structure of DNA. In this genome document all the genetic information required to create and sustain a human being was provided. The discovery of the structure of DNA has provided a foundation for a deeper understanding of all life forms, with DNA as a core molecule of genetic information. Of course that includes our food and our tiny friends of the microbial world. Further molecular technological advances in the fields of agriculture, food science, forensics, epidemiology, comparative genomics, medicine, diagnostics and therapeutics are providing stunning examples of the power of genomics in our daily lives. We are only now beginning to harvest the fruits of sequencing and using that knowledge routinely in our respective professions.
In our first column we wrote, “DNA sequencing can be used to determine the names, types, and proportions of microorganisms, the component species in a food sample, and track foodborne diseases agents.” In this month’s column, we present a basic guide to how DNA sequencing chemistry works.

DNA sequencing is the process of determining the precise order of four nucleotide bases, adenine or A, cytosine or C, guanine or G, and thymine or T in a DNA molecule. By knowing the linear sequence of A, C, G, and T in a DNA molecule, the genetic information carried in that particular DNA molecule can be determined.
DNA sequencing happened from the intersections of different fields including biology, chemistry, mathematics, and physics.1,2 The critical breakthrough was provided in 1953 by James Watson, Francis Crick, Maurice Wlkins and Rosalind Franklin when they resolved the now familiar double helix structure of DNA.3 Each helical strand was a polynucleotide, which consists of repeating monomeric units called nucleotides. A nucleotide consists of a sugar (deoxyribose), a phosphate moiety, and one of the four nitrogenous bases—the aforementioned A, C, G, and T. In the double helix, the strands run opposite to each other, commonly referred as anti-parallel. Repeating units of base-pairs (bp), where A always pairs with T and C always pairs with G, are arranged within the double helix so that they are slightly offset from each other like steps in a winding staircase. On a piece of paper, the double helix is often represented by scientists as a flat ladder-like structure, where the base pairs (bp) form the rungs of the ladder while the sugar-phosphate backbone form the antiparallel rails (see Figure 1).
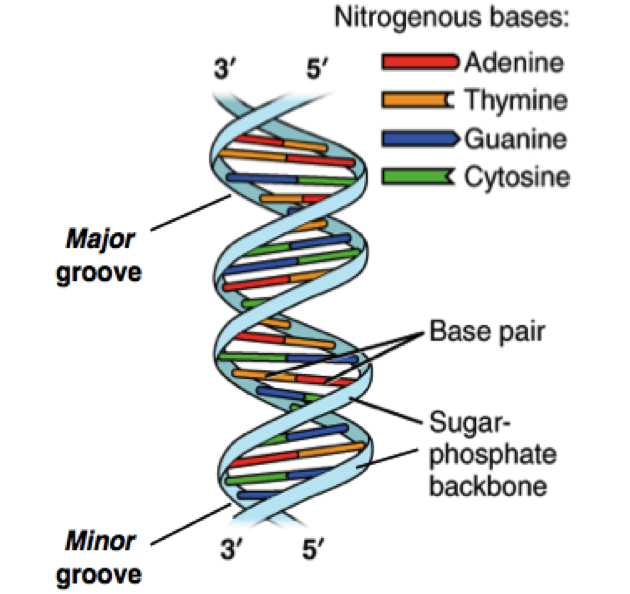
The two ends of each polynucleotide strand are called 5′ or 3′-end, a nomenclature that represents the chemical structure of the deoxyribose sugar at that terminus. The lengths of a single- or double-stranded DNA are often measured in bases (b) or bases pairs (bp), respectively. The two polynucleotide strands can be readily unzipped by heating, and on cooling, the initial double-helix structure is re-formed or re-annealed. The ability to rezip the initial ladder-like structure can be attributed to the phenomenon of base pairing, which merits repetition—the base A always pairs with T and the base G always with C. This rather innocuous phenomenon of base pairing is the basis for the mechanism by which DNA is copied when cells divide and is also the theoretical basis on which most traditional and modern DNA sequencing methodologies have been developed.
Other biological advancements also paved the way towards the development of sequencing technologies. Prominent amongst these were the discovery of enzymes that allowed a scientist to manipulate the DNA. For example, restriction enzymes that recognize and cleave DNA at specific short nucleotide sequences can be used to fragment a long duplex strand of DNA.4 The DNA polymerase enzyme, in the presence of the deoxyribose nucleotide triphosphates (dNTPs: Chemically reactive forms of the nucleotide monomers), can use a single DNA strand to fill in the complementary bases and extend a shorter rail strand (primer extension) of a partial DNA ladder.5 A critical part of the primer extension is the ‘primer’, which are short single-stranded DNA pieces (15 to 30 bases long) that are complementary to a segment of the target DNA. These primers are made using automated high-throughput synthesizer machines. Today, such primers can be rapidly manufactured and delivered on the following day. When the primer and the target DNA are combined through a process called annealing (heat and then cool), they form a structure that shows a ladder-like head and a long single-stranded tail. In 1983, Kary Mullis developed an enzyme-based process called Polymerase Chain Reaction (PCR). Using this protocol, one can pick a single copy of DNA and amplify the same sequence an enormous number of times. One can think of PCR as molecular photocopier in which a single piece of DNA is amplified up to approximately 30 billion copies!
The other critical event that changed the course of DNA sequencing efforts was the publication of the ‘dideoxy chain termination’ method by Dr. Frederick Sanger in December 1977.6 This marked the beginning of the first generation of DNA sequencing techniques. Most next-generation sequencing methods are refinements of the chain termination, or “Sanger method” of sequencing.
Frederick Sanger chemically modified each base so that when it was incorporated into a growing DNA chain, the chain was forcibly terminated. By setting up a primer extension reaction where in one of the chemically modified ‘inactive’ base in smaller quantity is mixed with four active bases, Sanger obtained a series of DNA strands, which when separated based on their size indicated the positions of that particular base in the DNA sequence. By analyzing the results from four such reactions run in parallel, each containing a different ‘inactive’ base, Sanger could piece together the complete sequence of the DNA. Subsequent modifications to the method allowed for the determination of the sequence using dye-labeled termination bases in a single reaction. Since, a sequence of less than <1000 bases can be determined from a single such reaction, the sequence of longer DNA molecules have to be pieced together from many such reads.
Using technologies available in the mid-1990’s, as many as 1 million bases of sequence could be determined per day. However, at this rate, determining the sequence of the 3 billion bp human genome required years of sequencing work. By analogy, this is equivalent to reading the Sunday issue of The New York Times, about 300,000 words, at a pace of 100 words per day. The cost of sequencing the human genome was a whopping $70 million. The human genome project clearly brought forth a need for technologies that could deliver fast, inexpensive and accurate genome sequences. In response, the field initially exploded with modifications to the Sanger method. The impetus for these modifications was provided by advances in enzymology, fluorescent detection dyes and capillary-array electrophoresis. Using the Sanger method of sequencing, one can read up to ~1,000 bp in a single reaction, and either 96 or 384 such reactions (in a 96 or 384 well plate) can be performed in parallel using DNA sequencers. More recently a new wave of technological sequencing advances, termed NGS or next-generation sequencing, have been commercialized. NGS is fast, automated, massively parallel and highly reproducible. NGS platforms can read more than 4 billion DNA strands and generate about a terabyte of sequence data in about six days! The whole 3 billion base pairs of the human genome can be sequenced and annotated in a mere month or less.
Our objective here is to provide a brief introduction to aspects of the technologies that are used for NGS. Execution of a sequencing project using any of the NGS technologies involves three steps:
- Library preparation: Generating small pieces of DNA so that they can be read in parallel
- Sequencing and imaging: Determining the sequence of the bases in immobilized DNA molecules in a massively parallel manner
- Data analysis a.k.a. bioinformatics: Piecing together the bits and pieces of the sequence collected in the second step into one logical, massive and contiguous sequence.
Before going much further, we have constructed a table of some important terms for your reference (see Table 1).
| Term | Brief Definition/Translation |
| Read Depth (or Sequencing Depth) | Number of times a sequence is determined for a single sample. A single read can have errors so multiple reads are desired for data quality. |
| Read Length | Length (bp) of an individual read |
| Coverage | A measure to determine the fraction of the total genome represented in the sequence data with a particular level of accuracy. |
| Library Preparation | The first step in the NGS workflow, which involves fragmenting the target DNA to a size compatible with the NGS platform and prepping the same for sequencing, i.e., by attaching adaptors. |
| Bp, Kb, Mb | A measure of read size or genome size: Base Pair, Kilobases (1,000 bp), Megabases (1 million bp). |
| Read Quality | Number of bp read errors in a sequence |
| FASTA and FASTQ files | Computer files containing the sequence |
| DNA Extraction | Wet chemistry protocol to remove high-quality DNA from a specimen |
| “Quality of DNA” | Indicators of quantity (ng/ml or ng’s) , purity and molecular weight of DNA extracted from a sample |
| “Just send me your DNA’s” | Refers to mailing or bringing DNA extracted from a sample to the sequencing lab |
| Table I. | |
During library preparation, genomic DNA is randomly broken into pieces typically <1,000 bp long, followed by ligation of adaptors (synthetic double stranded (ds) DNA fragments of known sequence) to the ends of the sheared DNA. A common theme across the NGS technologies is that millions of these adaptor-flanked DNA templates are attached to solid supports using different methods. This spatial distribution of immobilized templates allows for millions to billions of sequencing reactions to be run simultaneously. For example, in the first next-gen sequencers launched by the company 454 Life Sciences, tiny beads are used that contain several DNA strands complementary to a segment of the added-on adaptor, where the attachment of one template (piece of DNA to be sequenced) to one bead is achieved. Using PCR, multiple copies (millions) of each fragment of DNA tied to a bead are then generated on the surface of each bead.
While different NGS technologies use different sequencing chemistries to determine the sequence, all NGS protocols use smaller quantities of reagent per sequencing reaction than Sanger techniques and allow for multiple orders of increase in the amount of sequence data collected. Each of these advancements helps lower the cost of sequencing. Since sequencing reactions are performed using immobilized DNA fragments, the features of the recorded signal (typically fluorescence or light emitted during the extension of the primer) are on the scale of microns (i.e., smaller than the thickness of a human hair). Therefore, an image of reasonable surface area can provide information on millions of sequencing reactions being run in parallel. Picture a screen with many different colored dots appearing/disappearing in all parts of the screen, each representing a nucleotide base being detected and recorded into a sequence.
In case of the 454 Life Science sequencers, sequencing is conducted by a process called pyrosequencing, where a clever use of the luciferase enzyme makes every base incorporated give off a burst of light. In a single run, the 454 instrument can obtain around 400,000 reads at lengths of 200 to 400 bp. Several NGS platforms have emerged and have further reduced the cost of sequencing a genome (see Table 2).
| Platform | Instruments | Read Lengths (bp) |
| Illumina | MiniSeq, MiSeq, NextSeq, HiSeq, HiSeqX | 125–600 |
| Ion Torrent | Proton, PGM | 200–400 |
| Pacific Biosciences | PacBio RS, PacBio RS II | 4,600–14,000 |
| Roche 454 | GS FLX, GS FLX+ | 400–700 |
| SOLiD | 5500, 5500xI, 5500 W | 100 |
| Table 2. NGS Sequencing Platforms | ||
In the end, all of these instruments spit out a result that is generally in the form of a file type known as a FASTA or FASTQ (refer to Table 1). These files contain the sequence of ATCG’s in a sample and are the start of the bioinformatics process to be covered in a forthcoming addition to this column.
For the food safety professional, genomics investigations require accurate sequence information for reliable interpretation. Professionals are urged to consider certified sequencing providers that offer strong customer orientation, impeccable quality, fast service and high reliability. Poor quality sequence information can lead to poor quality species assignments in public databases. Faulty assignments lead to wrong bioinformatics interpretations. Recent highly sensationalized food genomics press releases showing the presence of difficult-to-believe contaminants, such as human or rat DNA in highly processed foods, may be due to analysis of poor quality sequence information. It is also recommended that professionals consult with organizations that know something about food science and technology to make sure sequence-based conclusions are based on a foundation of real and sound data.
References
- Hutchinson, C. A. III. (2007) DNA sequencing: bench to bedside and beyond. Nucleic Acids Res. 35, 6227–6237.
- Lee, T. F. (1991). The Human genome project; Cracking the genetic code of life.
- Watson, J. D. and Crick, F.H. (1953). A structure for deoxyribose nucleic acid. Nature. 171 (4356): 737–738.
- Smith, H. O. and Wilcox, K. W.(1970) A restriction enzyme from Hemophilus influenza I. Purification and general properties. J. Mol. Biol. 51, 379–391.
- Kaiser A D, Wu R (1968) Structure and function of DNA cohesive ends. Cold Spring Harb. Symp. Quant. Biol 1968;33:729-734.
- Sanger, F. et al. (1977) Nucleotide sequence of bacteriophage phi X174 DNA. Nature 265, 687–696.
Additional Resources
- Smith LM, Sanders JZ, Kaiser RJ, et al. (1986). “Fluorescence detection in automated DNA sequence analysis”. Nature. 321 (6071): 674–9.
- Ewing, B.; Hillier, L.; Wendl, M. C.; and Green, P. (1998). Base-calling of automated sequencer traces using Phred. I. Accuracy assessment. Genome Res. 8, 175–185.
This article was originally written by Sanjay K. Singh; Technical Marketing and Product Manager, Douglas Marshall Ph.D; Chief Scientific Officer, Gregory Siragusa; Senior Principal Scientist. The article is from FoodSafety Tech.